

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 투자 전략
- 바이오 투자
- 메모리 풀링
- 로봇 기술
- 투자 심리
- 분산 투자
- 리가켐바이오
- 주식투자
- 휴머노이드 로봇
- 펀더멘탈
- 스마트 팩토리
- 가치 투자
- ADC
- 신약 개발
- 주식 투자
- 재테크
- HBM
- AI 반도체
- LCB84
- 주식 차트 분석
- 인플레이션
- 엑시콘
- 로봇 산업
- 인공지능
- LCB39
- 눌림목 매매
- 미래 기술
- CXL 3.0
- 기술적 분석
- CXL
- Today
- Total
월가의 제갈공명
HBM과 2.5D 패키징 본문
요즘 뉴스에서 인공지능(AI)이나 엔비디아 이야기를 할 때 빠지지 않고 등장하는 단어가 있죠? 바로 HBM(High Bandwidth Memory)입니다. 저도 처음 이 용어를 접했을 때는 "그냥 빠른 메모리 아냐?"라고 생각했었는데요. 공부를 해보니 이건 단순한 속도 향상을 넘어선, 메모리 반도체 공학의 집념이 담긴 예술작품에 가깝더라고요. 😊
과거에는 CPU나 GPU 성능은 엄청나게 빠른데, 메모리가 그 속도를 따라가지 못해 병목 현상이 생기는 게 큰 고민이었어요. 이 문제를 해결하기 위해 메모리를 옆이 아닌 '위'로 쌓아 올리기 시작한 것이 HBM 역사의 시작입니다. 오늘은 이 흥미진진한 10년 넘는 여정을 함께 살펴볼까요?

1. HBM의 탄생: 불가능을 가능케 한 적층의 미학 🤔
HBM은 2013년 SK하이닉스가 세계 최초로 개발하며 세상에 알려졌습니다. 기존의 GDDR 메모리 방식으로는 데이터가 지나가는 통로(대역폭)를 넓히는 데 한계가 있었죠. 그래서 고안된 방법이 바로 TSV(Through Silicon Via, 실리콘 관통 전극) 공법입니다.
1. HBM 탄생 배경 (2010년대 초반)
문제는 이것이었습니다:
- GPU 연산 성능은 급증
- 메모리 대역폭은 병목
- 전력 소비 급증
- PCB 배선 길이 한계
👉 해결책:
메모리를 CPU/GPU 옆에 바로 붙이자
그래서 나온 것이:
- TSV(Through Silicon Via)
- 3D 적층
- 실리콘 인터포저 기반 패키징
메모리 칩에 수천 개의 미세한 구멍을 뚫어 상단과 하단 칩을 수직으로 연결하는 기술입니다. 기존 와이어 본딩 방식보다 데이터 전송 통로가 압도적으로 많아져 대역폭을 획기적으로 높일 수 있습니다.
처음 1세대 HBM이 등장했을 때 업계의 반응은 놀라움 그 자체였습니다. 기존 메모리 대비 크기는 훨씬 작아지면서도 속도는 몇 배나 빨라졌으니까요. 하지만 당시에는 공정이 워낙 까다롭고 가격이 비싸서 주로 하이엔드 그래픽 카드에만 제한적으로 사용되었습니다.
2. 세대별 진화 과정: HBM2에서 HBM3E까지 📊
1세대 이후 HBM은 매 세대마다 성능을 두 배 가까이 끌어올리며 진화했습니다. 2016년에 등장한 HBM2는 본격적으로 데이터센터와 슈퍼컴퓨터 시장을 공략하기 시작했고, 이때부터 삼성전자와 SK하이닉스의 기술 경쟁이 본격화되었죠.
HBM 주요 세대별 성능 비교표
세대 내부 구조 시스템 패키징 특징| HBM1 | 4-Hi 3D TSV | 2.5D 인터포저 | 최초 TSV 기반 |
| HBM2 | 8-Hi 3D | 2.5D | 대역폭 증가 |
| HBM2E | 8~12-Hi | 2.5D | AI 서버 확대 |
| HBM3 | 12~16-Hi | 2.5D | 800GB/s+ |
| HBM3E | 12~16-Hi | 2.5D | 1TB/s 접근 |
| HBM4 | 16-Hi 이상 | 2.5D (고도화) | 채널 증가 |
HBM은 일반적인 소비자용 PC 메인보드에 직접 꽂을 수 있는 형태가 아닙니다. GPU와 함께 하나의 패키지로 묶여 나오는 부품이므로, 개인용 업그레이드 품목과는 다릅니다.
HBM 3D 적층 유형
1. 메모리 단일종 적층 (Homogeneous 3D)
[ DRAM ]
[ DRAM ]
[ DRAM ]
[ DRAM ]
│
TSV
🔹 구성
- 동일 공정의 메모리 다이 (DRAM 또는 NAND)
- TSV(Through-Silicon Via)
- 마이크로 범프(또는 하이브리드 본딩)
🔹 사례
- HBM(내부 DRAM 4~16-Hi 이상)
- 3D NAND (100단~200단 이상)
📌 특징: 구조 단순, 열 관리 상대적으로 수월(연산 없음)
2. 메모리 + 로직 적층 (Heterogeneous 3D)
🔹 구조
메모리 위/아래에 로직 다이를 배치
-----------
[ Logic Die ]
🔹 구성
- DRAM 다이
- 로직 다이(제어·인터페이스)
- TSV 또는 하이브리드 본딩
🔹 사례
- HBM의 베이스(로직) 다이
- 3D V-Cache (CPU 위에 SRAM 적층)
📌 특징: 기능 분업 구조
📌 열 설계 중요
시스템 패키징 2D, 2.5D, 3D(현재 불가능) 차이
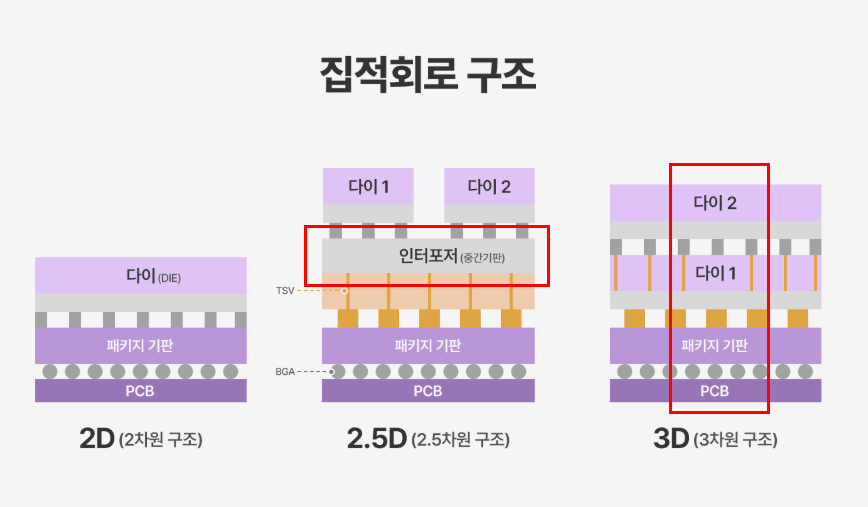
1. 2D 구조 (전통적 패키징)
🔹 개념
- 칩을 PCB(기판) 위에 나란히 배치
- 배선은 기판을 통해 연결
🔹 특징
- 구조 단순
- 비용 저렴
- 배선 길이 김 → 신호 지연 발생
- 대역폭 한계
🔹 예시
- 일반 CPU + DDR 메모리 구조
스마트폰 SoC + LPDDR
2. 2.5D 구조 (인터포저 기반)
🔹 개념
- 칩을 실리콘 인터포저 위에 나란히 배치
- 인터포저 안에 미세 배선 존재
🔹 특징
- 칩은 “수평 배치”
- 배선 길이 매우 짧음
- 수천~수만 개 I/O 가능
- 초고대역폭 구현 가능
- 비용 높음
🔹 대표 사례
- TSMC CoWoS
- NVIDIA AI GPU + HBM
📌 HBM 구조는 대부분 2.5D
3. 3D 구조 (수직 적층)
🔹 개념
- 칩을 수직으로 직접 적층
- TSV(Through Silicon Via) 사용
[ Chip ]
[ Chip ]
│
TSV 수직 연결
🔹 특징
- 배선 길이 가장 짧음
- 지연 최소
- 집적도 최고
- 열 문제 심각
- 제조 난이도 매우 높음
🔹 대표 사례
- HBM 내부 DRAM 적층
- 3D NAND
- 일부 CPU 캐시 적층
🔹 한눈에 비교
| 배치 | 수평 | 수평 + 인터포저 | 수직 |
| 배선 길이 | 김 | 짧음 | 매우 짧음 |
| 대역폭 | 낮음 | 매우 높음 | 최고 |
| 발열 | 관리 쉬움 | 중간 | 어려움 |
| 난이도 | 낮음 | 높음 | 매우 높음 |
| 예시 | CPU+DDR | GPU+HBM | HBM 내부 |
🔹 왜 GPU는 3D로 안 쌓나?
- GPU 발열 수백 와트
- HBM은 열에 민감
- 대형 다이 수직 적층은 수율 문제
그래서 현재는 GPU+HBM = 2.5D
HBM 내부만 3D
🔹 핵심 정리
2D = 전통적 평면 배치
2.5D = 인터포저 위 수평 고대역폭 연결
3D = 칩을 직접 수직 적층
3. HBM 대역폭이 중요한 이유 🧮
AI 모델이 커질수록 학습해야 할 데이터의 양은 기하급수적으로 늘어납니다. 이때 데이터를 얼마나 빨리 메모리에서 꺼내 GPU로 전달하느냐가 전체 시스템 성능을 결정합니다. 초당 1.2테라바이트(TB)라는 속도가 어느 정도인지 감이 오시나요?
📝 대역폭 체감 예시
HBM3E 대역폭(1.2TB/s) = 풀HD 영화(5GB) 약 240편을 단 1초 만에 전송 가능한 속도
🔢 데이터 전송 시간 계산기
데이터 용량을 입력하면 HBM 세대별로 전송에 걸리는 시간을 계산해 줍니다.
4. 미래를 향한 경쟁: HBM4와 그 너머 👩💼👨💻
현재 업계의 시선은 2025~2026년 상용화될 6세대 HBM4로 향하고 있습니다. HBM4의 가장 큰 특징은 메모리 업체와 파운드리(반도체 위탁생산) 업체의 협력이 필수적이라는 점인데요. 로직 다이(Logic Die)라고 불리는 하단 칩을 더 미세한 공정으로 만들기 위해서입니다.
HBM4부터는 '커스텀 HBM' 시대가 열립니다. 고객사(예: 엔비디아, 구글 등)의 요구에 맞춰 하단 로직 다이를 맞춤 설계하기 때문에, 단순히 만드는 능력을 넘어선 설계 협력이 핵심 경쟁력이 될 전망입니다.
HBM 발달사 핵심 요약
자주 묻는 질문 ❓
단순히 용량을 늘리는 경쟁을 넘어, 이제는 데이터를 전송하는 '길'을 어떻게 만드느냐가 반도체의 핵심이 된 시대입니다. HBM의 역사를 보면 우리 기업들이 얼마나 치열하게 기술의 한계를 돌파해 왔는지 알 수 있어 가슴이 웅장해지기도 하네요. 😊
여러분은 HBM 기술이 앞으로 우리 삶을 또 어떻게 바꿔놓을 것 같나요? 궁금한 점이나 의견이 있다면 언제든 댓글로 남겨주세요! 긴 글 읽어주셔서 감사합니다.
⚠️ 면책조항
본 내용은 참고용 초안으로, 사실과 다른 정보가 포함될 수 있습니다. 동일한 내용을 여러 증권전문가가 분석해도 각자 다른 관점과 결론을 제시하는 것처럼, 본 분석 역시 매번 해석 방식이나 강조점이 달라질 수 있습니다. 따라서, 제시된 모든 내용은 반드시 본인의 직접 검증해야 하며, 투자의 최종 결정과 책임은 사용자 본인에게 있습니다.
'투자' 카테고리의 다른 글
| [2026년 02월 28일] 내일 상승 유망 TOP 10 분석 (0) | 2026.02.28 |
|---|---|
| [2026년 2월 26일] 미 증시 분석 및 TOP 10 종목 (0) | 2026.02.26 |
| D램 10나노급 세대 구분 (0) | 2026.02.25 |
| [2026년 02월 25일] 내일 상승 유망 TOP 10 분석 (0) | 2026.02.25 |
| [2026년 2월 25일] 미 증시 분석 및 TOP 10 종목 (0) | 2026.02.25 |



