

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 스마트 팩토리
- 주식투자
- 투자 심리
- 분산 투자
- 미래 기술
- AI 반도체
- 리가켐바이오
- ADC
- CXL
- LCB39
- LCB84
- 신약 개발
- 인플레이션
- 주식 투자
- CXL 3.0
- 로봇 산업
- 눌림목 매매
- 엑시콘
- 가치 투자
- 주식 차트 분석
- 인공지능
- 메모리 풀링
- 휴머노이드 로봇
- 재테크
- 로봇 기술
- 바이오 투자
- 펀더멘탈
- HBM
- 기술적 분석
- 투자 전략
- Today
- Total
월가의 제갈공명
AI 성능의 한계 '메모리 벽'을 허무는 혁신 기술 3가지와 삼성전자 본문
여러분, 요즘 AI가 못 하는 게 없다는 생각이 들지 않으시나요? 글도 쓰고 그림도 그리고, 심지어 코딩까지 척척 해내는 걸 보면 정말 세상이 변했다는 게 실감 나요. 하지만 이렇게 똑똑한 AI 모델이 돌아가기 위해서는 보이지 않는 곳에서 반도체들이 엄청나게 고생하고 있다는 사실, 알고 계셨나요? 😊
솔직히 말해서, 우리가 ChatGPT 같은 서비스를 편하게 쓰는 동안 서버실의 GPU들은 뜨거운 열기를 내뿜으며 데이터와 사투를 벌이고 있어요. 모델은 기하급수적으로 커지는데, 정작 데이터를 나르는 반도체 기술이 그 속도를 따라가지 못해 생기는 '병목 현상'이 현재 AI 산업의 가장 큰 화두랍니다. 오늘은 이 복잡한 반도체 이야기를 아주 쉽게, 그리고 핵심만 콕콕 집어서 풀어볼게요!
1. 왜 AI는 자꾸 느려질까요? '메모리 벽'의 정체 🤔
AI 연산의 핵심은 수많은 데이터를 빠르게 계산하는 것입니다. 하지만 여기서 큰 문제가 발생해요. 바로 폰 노이만 구조의 한계 때문입니다. 우리가 흔히 쓰는 컴퓨터 구조는 연산을 담당하는 프로세서(GPU)와 데이터를 저장하는 메모리(DRAM)가 떨어져 있어요.
비유하자면, 요리사는 엄청나게 빠른데 재료를 가져오는 통로가 너무 좁아서 요리사가 계속 기다려야 하는 상황인 거죠. 이를 반도체 업계에서는 '메모리 벽(Memory Wall)'이라고 부릅니다. 연산 장치의 속도는 수백 배 빨라졌지만, 메모리에서 데이터를 가져오는 속도는 그만큼 빨라지지 못했거든요.
1. 데이터 이동 오버헤드: 연산 시간보다 데이터를 옮기는 데 더 많은 시간과 에너지가 소모됨.
2. 낮은 대역폭: 한 번에 보낼 수 있는 데이터 양의 한계.
3. 전력 소모: 데이터 이동 과정에서 발생하는 열과 전기 소모가 시스템 안정성을 저해함.
2. 고속도로를 넓혀라! HBM과 CXL 솔루션 📊
이 병목을 해결하기 위해 등장한 구원투수가 바로 HBM(고대역폭 메모리)입니다. 기존에는 메모리를 옆으로 나열했다면, HBM은 메모리를 아파트처럼 수직으로 쌓아 올린 뒤 수천 개의 구멍을 뚫어 데이터를 수송합니다. 덕분에 데이터 통로가 획기적으로 넓어졌죠.
여기에 더해 최근 주목받는 기술이 CXL(Compute Express Link)입니다. HBM이 전용 고속도로라면, CXL은 시스템 전체의 메모리를 하나의 큰 저수지처럼 공유해서 효율적으로 나눠 쓰는 기술이에요. 메모리 용량 부족 문제를 해결할 핵심 열쇠로 꼽히고 있습니다.
1️⃣ 메모리 병목
HBM4 + CXL 3.0 → 대역폭·용량 동시 확장
🔹 문제의 본질
- AI 성능 병목은 연산이 아니라 데이터를 얼마나 빨리, 많이 가져오느냐
- HBM은 빠르지만:
- 용량 한계
- 가격·전력 부담
- 컨텍스트·추론 데이터가 폭증하면서 GPU 대기 시간 증가
🔹 해결 방향
- HBM4
- 더 넓은 인터페이스
- 더 높은 대역폭
- GPU–메모리 간 병목 완화
- CXL 3.0
- 메모리 풀링·공유
- 외부 DRAM·스토리지를 GPU가 직접 활용
- “HBM 부족 문제를 구조적으로 제거”
🔹 의미
HBM은 ‘단기 기억’, CXL은 ‘기억의 확장 통로’
→ 메모리 병목은 확장성의 문제로 전환됨
📊 AI에서 말하는 ‘병목(bottleneck)’의 진짜 원인
AI 병목의 해결책은 “더 빠른 GPU”가 아니라
“기억을 다루는 방식 자체를 바꾸는 것”입니다.
1️⃣ 해결 전략의 한 줄 요약
GPU 중심 구조 → 메모리·스토리지 중심 구조
연산은 GPU가, 기억은 계층적으로 분산시켜 맡깁니다.
2️⃣ AI 병목 해결의 5대 핵심 솔루션
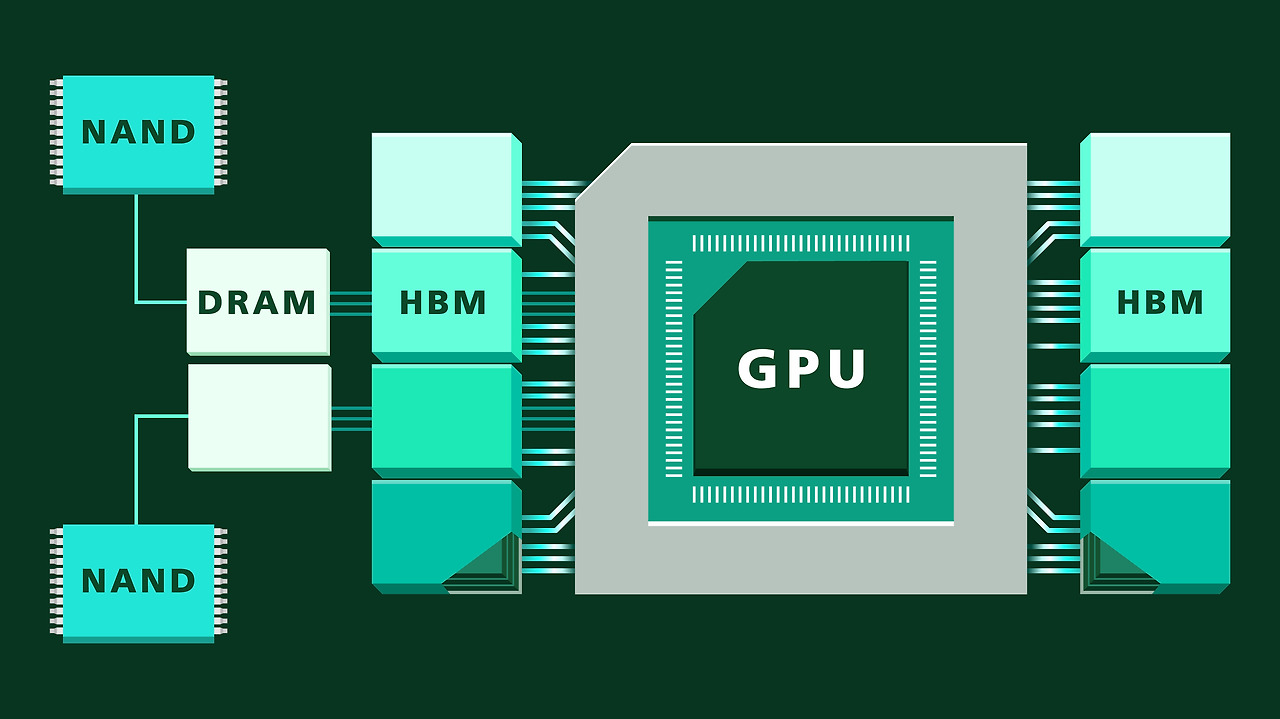
① 메모리 계층화 (Memory Hierarchy 재설계)
기존:
- 모든 걸 HBM에 넣으려다 붕괴
개선:
- HBM → 초단기 기억 (지금 계산 중인 데이터)
- DRAM → 중기 기억
- ESSD → 장기 기억 (컨텍스트·히스토리·대규모 상태)
👉 비싼 기억은 꼭 필요한 만큼만 사용
② 스토리지의 메모리화 (ESSD 활용)
- ESSD를 단순 저장소가 아니라 **‘확장 메모리’**로 사용
- 대화 이력, 벡터DB, 추론 상태를 실시간 로딩
효과:
- HBM 부족 문제 해소
- 동시 사용자 수 증가
- GPU 대기 시간 감소
③ CXL 도입 (Compute Express Link)
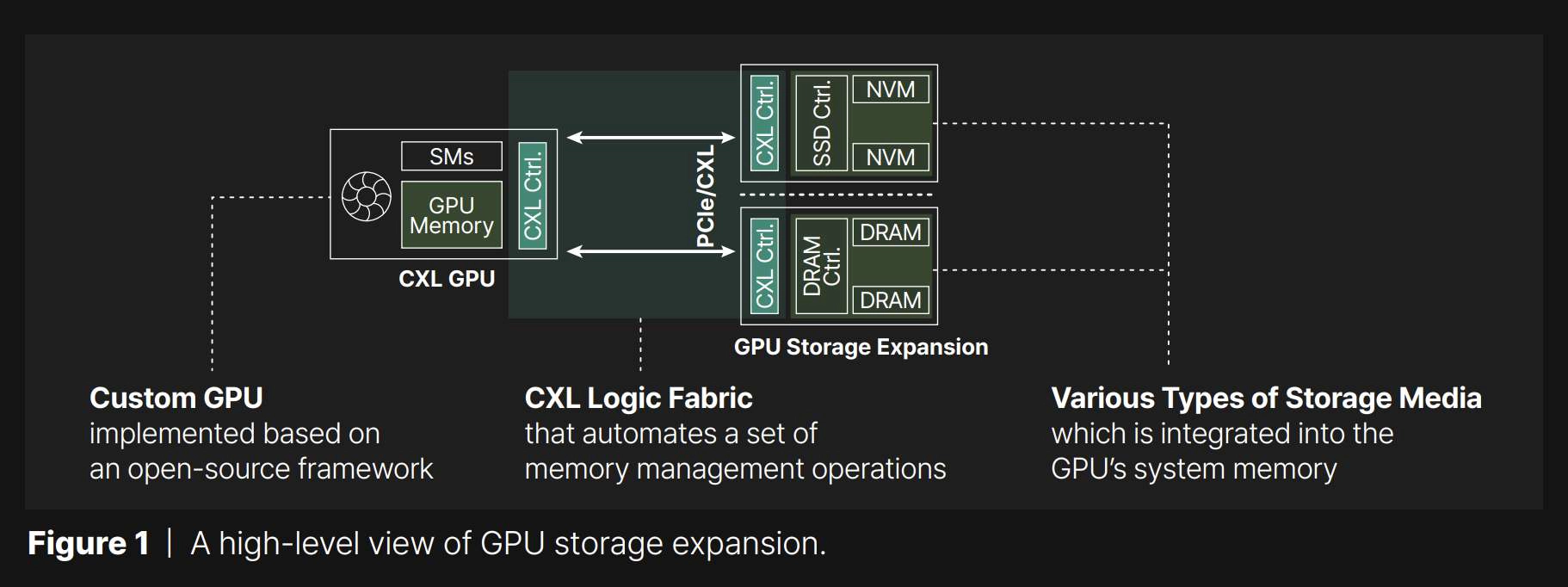
- GPU가 외부 메모리·스토리지를
자기 몸 안 메모리처럼 접근 - 메모리 풀링, 공유, 확장 가능
👉 메모리 병목 자체를 제거
④ 추론 특화 아키텍처 (Inference-First Design)
- 학습 중심 → 추론 중심으로 전환
- 목표:
- 전력 ↓
- 지연 ↓
- 비용 ↓
- GPU 활용률 극대화보다
시스템 전체 효율 최적화
⑤ 데이터 이동 최소화 (Energy-Aware Architecture)
- 병목의 또 다른 본질 = 데이터 이동
- 해결:
- 가까운 곳에 데이터 배치
- 불필요한 재전송 제거
- 연산보다 데이터 흐름 최적화
결과:
- 전력 소비 대폭 감소
- 냉각 비용 절감
- 데이터센터 TCO 하락
3️⃣ “잘못된 해결책 vs 진짜 해결책”
| GPU 더 추가 | 기억 구조 재설계 |
| HBM만 확대 | 메모리 계층화 |
| 연산 성능 경쟁 | 효율 경쟁 |
| 학습 위주 설계 | 추론 위주 설계 |
4️⃣ 왜 이게 산업 판도를 바꾸는가
- AI 사용자는 폭발적으로 증가
- AI 서비스는 24/7 실시간
- 비용·전력·확장성이 승부처
→ 시스템 효율을 바꾸는 기업이 승자
이 흐름 속에서 NVIDIA의 차세대 플랫폼은
GPU 성능 경쟁이 아니라 기억 구조 혁신에 초점을 둡니다.
5️⃣ 최종 결론 (가장 중요한 문장)
AI 병목의 해답은
“GPU를 더 빠르게”가 아니라
“기억을 더 똑똑하게 쓰는 것”입니다.
AI 메모리 기술 비교 📝
| 기술명 | 핵심 역할 | 장점 |
|---|---|---|
| HBM | 압도적인 데이터 전송 속도 | 초고속 대역폭 제공 |
| CXL | 메모리 용량 확장 및 공유 | 시스템 효율성 극대화 |
| PIM | 메모리 내 연산 수행 | 데이터 이동 최소화, 저전력 |
📊 메모리와 저장장치의 차이
모리는 ‘지금 생각하는 공간’이고, 저장장치는 ‘기억을 보관하는 공간’입니다.
1️⃣ 한 줄 정의
- 메모리(Memory)
→ CPU·GPU가 지금 당장 계산에 쓰는 작업 공간 - 저장장치(Storage)
→ 계산이 끝난 데이터나 나중에 쓸 정보를 오래 보관하는 공간
2️⃣ 구조 차이 한눈에 보기
| 기본 목적 | 즉시 연산용 작업 공간 | 장기 데이터 보관 |
| 물리적 위치 | CPU/GPU 바로 옆 | 시스템 외부 (PCIe / CXL) |
| 접근 방식 | Load / Store (직접 접근) | I/O 요청 기반 |
| 접근 지연 | ns ~ µs | µs ~ ms |
| 대역폭 | 매우 높음 | 상대적으로 낮음 |
| 용량 확장성 | 매우 제한적 | 매우 큼 |
| 비용/GB | 매우 비쌈 | 저렴 |
| 전원 차단 시 | 데이터 소실 | 데이터 유지 |
| 데이터 성격 | 중간 계산값, 활성 컨텍스트 | 히스토리, 장기 컨텍스트 |
| 동시 접근성 | 제한적 | 높음 |
| 병목 발생 지점 | 용량·비용 | 지연·I/O |
| AI에서 역할 | 단기 기억 (Working Memory) | 장기 기억 (Long-term Memory) |
| 확장 방식 | 패키징·적층 한계 | 슬롯·랙 단위 확장 |
| 병목 해결 방향 | 계층화·CXL | 메모리화·저지연화 |
핵심 구조 차이 한 문장 요약
메모리는 “속도를 위해 태어난 공간”,
저장장치는 “용량을 위해 태어난 공간”입니다.
AI 시대에는 이 둘이 분리될 수 없기 때문에
👉 메모리는 작고 빠르게,
👉 저장장치는 크고 메모리처럼 진화하고 있습니다.
3️⃣ 핵심 차이 비교 표
| 역할 | 즉시 계산 | 장기 보관 |
| 접근 속도 | 매우 빠름 (ns~µs) | 느림 (µs~ms) |
| 용량 | 작음 | 큼 |
| 가격/GB | 매우 비쌈 | 상대적으로 저렴 |
| 전원 OFF | 데이터 소실 | 데이터 유지 |
| CPU/GPU 접근 | 직접 | I/O 경유 |
4️⃣ 왜 이렇게 나뉘어 있을까?
▶ 메모리
- 연산 속도를 맞추기 위해 극단적으로 빠름
- 대신:
- 비쌈
- 용량 작음
- 전원 끄면 사라짐
👉 “속도를 위해 희생한 저장성”
▶ 저장장치
- 데이터를 안전하고 많이 저장
- 대신:
- 속도 느림
- 계산에는 부적합
👉 “보관을 위해 희생한 속도”
5️⃣ AI 시대에 문제가 된 지점
기존 컴퓨터 설계는:
- 메모리 = 조금만 있으면 충분
- 저장장치 = 그냥 창고
하지만 AI는 다릅니다.
AI의 특징
- 기억해야 할 데이터가 폭발적
- 대화·추론·컨텍스트 유지 필수
- 메모리에 다 못 올림
👉 메모리는 부족하고, 저장장치는 너무 느림
이게 바로 AI 병목의 출발점입니다.
6️⃣ 그래서 등장한 새로운 개념
🔄 “저장장치의 메모리화”
- SSD를 단순 창고가 아니라
- 메모리처럼 빠르게
- 자주 접근 가능하게 사용
🔗 CXL 같은 기술
- 저장장치·외부 메모리를
CPU/GPU가 직접 쓰는 것처럼 접근
👉 메모리와 저장장치의 경계가 무너지기 시작
7️⃣ AI 관점에서 다시 정리
| 왜 메모리만 늘리면 안 되나? | 너무 비싸고 물리적 한계 |
| 왜 저장장치를 쓰게 됐나? | 용량·비용 문제 해결 |
| 핵심은? | 속도와 용량의 균형 |
8️⃣ 최종 정리 (가장 중요한 문장)
메모리는 ‘생각하는 공간’,
저장장치는 ‘기억하는 공간’.
AI 시대에는 이 둘을 분리해서 쓸 수 없게 되었습니다.
그래서 앞으로의 AI 아키텍처 핵심은
👉 **“저장장치를 얼마나 메모리처럼 쓰느냐”**입니다.
3. 생각을 하는 메모리, PIM의 혁명 🧮
병목을 해결하는 가장 공격적인 방법은 뭘까요? 바로 메모리 자체가 계산을 직접 하는 것입니다. 이것이 바로 PIM(Processor-In-Memory) 기술입니다. 데이터를 옮길 필요 없이 저장된 장소에서 바로 처리해버리니 속도는 빠르고 전력 소모는 획기적으로 줄어듭니다.
2️⃣ 연산 효율
PIM + NPU 고도화 → 전력 대비 성능 극대화
🔹 문제의 본질
- AI 데이터센터의 최대 비용은:
- 연산 자체보다 전력·발열·냉각
- 기존 구조:
- 데이터 이동 → 연산 → 다시 이동
- 이동 비용이 연산 비용을 압도
🔹 해결 방향
- PIM (Processing-In-Memory)
- 메모리 내부에서 연산 수행
- 데이터 이동 최소화
- NPU 고도화
- 범용 GPU 대비
- 전력 효율 ↑
- 추론 특화 처리
- 범용 GPU 대비
- “연산을 잘하는 칩”보다
**“덜 움직이고 계산하는 구조”**가 중요
🔹 의미
AI 성능 경쟁 → 전력 효율 경쟁
→ 와트당 성능(Watt/Performance)이 핵심 지표로 이동
사례 연구: PIM의 효과 📝
실제로 삼성전자의 HBM-PIM 기술을 적용했을 때, 기존 시스템 대비 성능은 약 2배 이상 향상되고 에너지는 70% 이상 절감되는 결과가 보고되기도 했습니다. 데이터 센터의 전기료 걱정을 덜어줄 효자 종목이죠!
4. 제조 공정의 끝판왕, 첨단 패키징(CoWoS) 👩💼👨💻
반도체 칩 자체를 잘 만드는 것도 중요하지만, 이제는 여러 칩을 어떻게 잘 이어 붙이느냐가 더 중요해졌습니다. 엔비디아의 GPU가 왜 그렇게 구하기 힘든지 아시나요? 바로 TSMC의 CoWoS(Chip on Wafer on Substrate)라는 패키징 공정의 수율이 수요를 못 따라가기 때문입니다.
3️⃣ 공급 안정
CoWoS 등 첨단 패키징 캐파 확보 + 수율 개선
🔹 문제의 본질
- AI 반도체는 이제
- 단일 칩이 아니라
- 패키지 완성도가 성능과 물량을 결정
- 병목은 공정이 아니라:
- 패키징 캐파
- 수율
- 납기
🔹 해결 방향
- CoWoS (2.5D/3D 패키징)
- GPU + HBM 고밀도 집적
- 신호 지연 최소화
- 캐파 확대 + 수율 안정
- “만들 수 있느냐”보다
- “제때, 충분히 공급하느냐”가 경쟁력
🔹 의미
AI 반도체 경쟁은 기술력 + 생산 체력의 싸움
→ 공급망을 장악한 쪽이 시장을 지배
반도체 성능이 아무리 좋아도 패키징 기술이 뒷받침되지 않으면 무용지물입니다. 2026년까지도 이 패키징 공정이 전체 AI 반도체 공급의 주요 병목이 될 것으로 전망되고 있습니다.
AI 반도체 3대 해결 과제
4️⃣ 세 과제가 연결되는 구조
| 메모리 병목 | HBM4 · CXL | 확장성 확보 |
| 연산 효율 | PIM · NPU | 전력 비용 절감 |
| 공급 안정 | CoWoS · 수율 | 시장 지배력 |
👉 셋 중 하나라도 빠지면 AI 스케일업 불가능
5️⃣ 한 문장 결론
AI 반도체의 승자는
더 빠른 칩을 만드는 회사가 아니라
‘기억·연산·공급’을 동시에 통제하는 회사입니다.
📊 블랙웰과 루빈의 아키텍처 차이
블랙웰은 ‘GPU를 더 강하게 쓰는 구조’이고, 루빈은 ‘GPU 의존도를 낮추고 시스템 전체를 바꾸는 구조’입니다.
🧠 기본 전제 (왜 아키텍처가 바뀌었나)
현재 AI 병목은 연산이 아니라 기억(메모리·스토리지) 입니다.
이를 인식한 NVIDIA는 GPU 중심 구조 → 메모리·스토리지 중심 구조로 축을 이동시켰습니다.
1️⃣ 블랙웰 아키텍처 (Blackwell)
▶ 구조적 특징
- HBM 중심 설계
- GPU 옆의 초고속 HBM(HBM3E 등)에 최대한 많은 데이터 적재
- GPU 스케일업 전략
- 더 많은 GPU, 더 빠른 인터커넥트(NVLink)
- 메모리는 ‘보조 역할’
- SSD는 저장소, DRAM/HBM이 사실상 전부
▶ 한계
- HBM은 비싸고 용량이 작음
- 추론(Inference) 단계에서 컨텍스트 길이·동시 사용자 수 한계
- GPU 비용·전력·발열 급증
👉 훈련(Training)에는 강하지만, 대규모 추론에는 비효율
2️⃣ 루빈 아키텍처 (Rubin)
▶ 구조적 혁신
- ICMS (In-Context Memory & Storage)
- SSD를 단순 저장장치가 아니라 ‘메모리처럼 사용’
- HBM은 단기 기억
- “지금 계산 중인 데이터만” 유지
- ESSD는 장기 기억
- 수 TB~PB급 컨텍스트를 실시간 호출
- CXL 기반 확장
- 메모리·스토리지를 GPU 외부 자원처럼 자유롭게 공유
▶ 결과
- GPU 활용률 ↑
- 동시 사용자 수 ↑
- 전력 소비 ↓
- 시스템 TCO(총소유비용) 대폭 감소
👉 추론(Inference) 특화 아키텍처
3️⃣ 핵심 차이 한눈에 비교
| 설계 철학 | GPU 성능 극대화 | 시스템 효율 극대화 |
| 메모리 전략 | HBM 중심 | HBM + ESSD 계층화 |
| SSD 역할 | 저장용 | 메모리 확장 |
| 병목 해결 | 더 빠른 GPU | 기억 구조 재설계 |
| 주력 용도 | 학습(Training) | 추론(Inference) |
| 비용 구조 | GPU·HBM 고비용 | 스토리지로 비용 절감 |
4️⃣ 왜 “루빈부터 게임이 바뀐다”는 말이 나오는가
- AI 산업의 중심이 학습 → 추론으로 이동
- 추론은:
- 사용자 수 많음
- 컨텍스트 길이 김
- 전력·비용 민감
- → GPU만으로는 해결 불가
- → 스토리지·메모리 구조가 주인공으로 등판
즉,
루빈은 GPU 아키텍처가 아니라 ‘AI 데이터센터 아키텍처’입니다.
5️⃣ 한 줄 결론 (투자·기술 관점)
- 블랙웰: “GPU 왕국의 완성판”
- 루빈: “GPU 왕국을 지탱하는 경제 시스템”
📊 루빈에서 ESSD가 왜 삼성 독점 구조인가
루빈(Rubin)에서 ESSD는 ‘성능’이 아니라
‘동시에 만족해야 하는 조건의 개수’ 때문에 삼성 독점 구조가 됩니다.
아래에서 왜 다른 회사들이 구조적으로 따라올 수 없는지를 차근히 정리하겠습니다.
1️⃣ 루빈이 ESSD에 요구하는 조건이 ‘비정상적으로 높다’
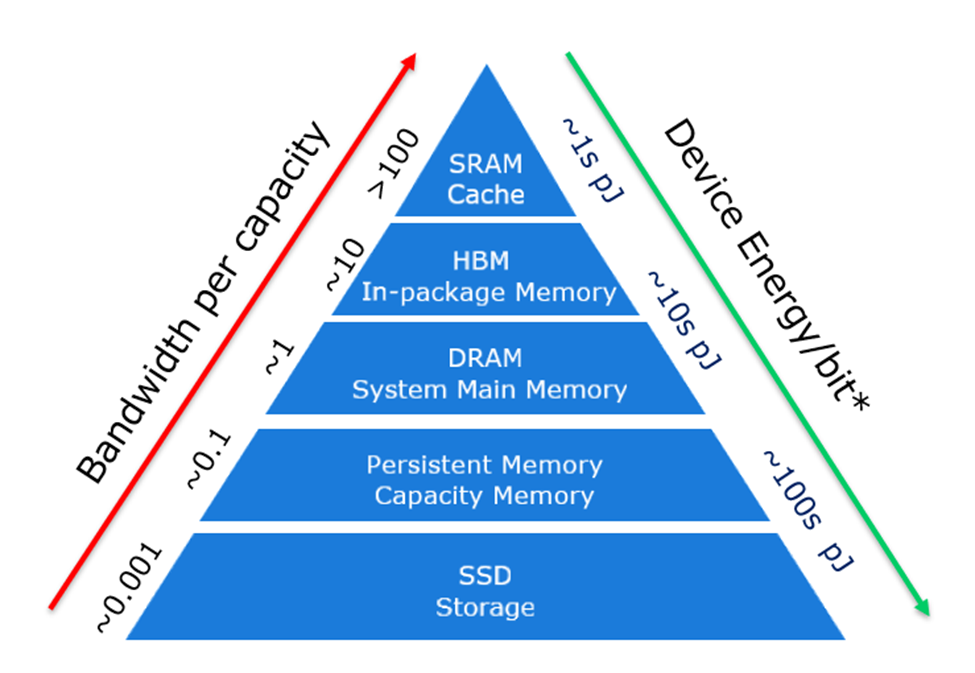
루빈의 ICMS(In-Context Memory & Storage) 구조에서 ESSD는 단순 저장장치가 아닙니다.
아래 조건을 동시에 만족해야 합니다.
| 초저지연 | 메모리처럼 써야 함 |
| 초고용량 | 수십~수백 TB 단일 드라이브 |
| 초고내구 | 24/7 AI 추론 워크로드 |
| 초저전력 | 데이터센터 TCO 직결 |
| 대량 공급 | 수만~수십만 대 단위 |
| CXL/시스템 최적화 | GPU와 실시간 연동 |
👉 한두 개가 아니라 ‘모두’ 충족해야 함
2️⃣ 삼성만 가능한 이유 ①
NAND → 컨트롤러 → 펌웨어 → 파운드리 완전 수직계열화
- 삼성은:
- NAND Flash
- SSD 컨트롤러
- 펌웨어
- 파운드리 공정
전부를 내부에서 설계·제조
다른 경쟁사들은:
- NAND는 있어도 → 컨트롤러 외주
- 컨트롤러는 있어도 → 파운드리 외주
- 파운드리는 있어도 → NAND 없음
👉 루빈처럼 “GPU에 맞춰 SSD를 튜닝”해야 하는 구조에서는
외주 구조 자체가 치명적 한계
3️⃣ 삼성만 가능한 이유 ②
‘메모리처럼 쓰는 SSD’ 설계 경험
루빈 ESSD는:
- 읽기 속도만 빠르면 ❌
- 지연 분산(latency jitter) 이 낮아야 함
- 메모리 계층에 자연스럽게 편입돼야 함
삼성은 이미:
- PM1733 / PM1743 / PM1753 계열로
- AI 서버 실증 데이터를 축적
- GPU–스토리지 협업 최적화 경험 보유
👉 경쟁사는 아직 “빠른 SSD” 단계
👉 삼성은 이미 “메모리형 SSD” 단계
4️⃣ 삼성만 가능한 이유 ③
CXL 시대에 맞는 컨트롤러·공정 대응력
루빈 이후 ESSD는:
- CXL과 결합
- SSD 컨트롤러가 시스템 반도체가 됨
이때 중요한 것:
- 미세 공정
- 전력 효율
- SoC 수준 통합
삼성은:
- 차세대 SSD 컨트롤러를
- **자체 파운드리(최첨단 노드)**에서 생산 가능
👉 경쟁사:
- TSMC 캐파 대기
- 우선순위 밀림
- 일정·물량 불확실
5️⃣ 삼성만 가능한 이유 ④
물량이 ‘기술 장벽’이 되는 구간
루빈 서버 1대당:
- 1PB(≈1,000TB) 이상 SSD 요구
NVIDIA 입장에서 중요한 건:
- “가장 좋은 SSD” ❌
- “이 물량을 제때, 계속 공급 가능한 SSD” ⭕
현재:
- 글로벌 NAND 생산 능력
- 엔터프라이즈 SSD 캐파
- 품질 인증 경험
이 세 가지를 동시에 갖춘 곳은
👉 사실상 삼성전자뿐
6️⃣ 왜 ‘경쟁사가 따라오면 되지 않나?’가 안 되는가
| 기술 추격 | 2~3년 |
| 컨트롤러 재설계 | 1~2년 |
| 파운드리 확보 | 불확실 |
| 대량 검증 | 추가 1년 |
👉 루빈 → 루빈 후속 세대까지 이미 끝
7️⃣ 구조적으로 정리하면
루빈에서 ESSD는
**부품이 아니라 ‘플랫폼 구성 요소’**이며,
플랫폼 레벨에서 맞춤 설계·공급 가능한 기업은
삼성전자 하나뿐입니다.
8️⃣ 한 줄 결론 (가장 중요)
루빈의 ESSD는
“삼성이 잘해서”가 아니라
“삼성만 가능하게 설계된 구조”입니다.
자주 묻는 질문 ❓
마무리하며: 반도체가 그리는 AI의 미래 📝
결국 인공지능의 한계는 반도체의 한계와 맞닿아 있습니다. 소프트웨어가 아무리 똑똑해져도 그것을 담아낼 그릇인 반도체가 부족하거나 느리다면 발전은 멈출 수밖에 없거든요. 하지만 우리가 살펴본 것처럼 HBM, CXL, PIM 등 수많은 혁신이 이 병목을 뚫기 위해 대기 중입니다.
반도체 기술의 진보를 지켜보는 것만으로도 미래 AI가 얼마나 더 강력해질지 짐작해 볼 수 있어 정말 흥미진진하네요! 여러분은 어떤 기술이 가장 기대되시나요? 더 궁금한 점이 있다면 댓글로 자유롭게 남겨주세요~ 😊
⚠️ 면책조항
본 내용은 참고용 초안으로, 사실과 다른 정보가 포함될 수 있습니다. 동일한 내용을 여러 증권전문가가 분석해도 각자 다른 관점과 결론을 제시하는 것처럼, 본 분석 역시 매번 해석 방식이나 강조점이 달라질 수 있습니다. 따라서, 제시된 모든 내용은 반드시 본인의 직접 검증해야 하며, 투자의 최종 결정과 책임은 사용자 본인에게 있습니다.
'투자' 카테고리의 다른 글
| CXL 기술과 국내 수혜주 (0) | 2026.01.29 |
|---|---|
| PIM 반도체란? AI 시대 HBM 다음을 이끌 핵심 기술과 수혜주 정리 (1) | 2026.01.29 |
| [2026년 1월 29일] 내일 상승 유망 TOP 10 분석 (0) | 2026.01.29 |
| [2026년 1월 29일] 미 증시 분석 및 TOP 10 종목 (1) | 2026.01.29 |
| [2026년 1월 28일] 내일 급등 유망 한국 주식 TOP 10 분석 (0) | 2026.01.28 |



